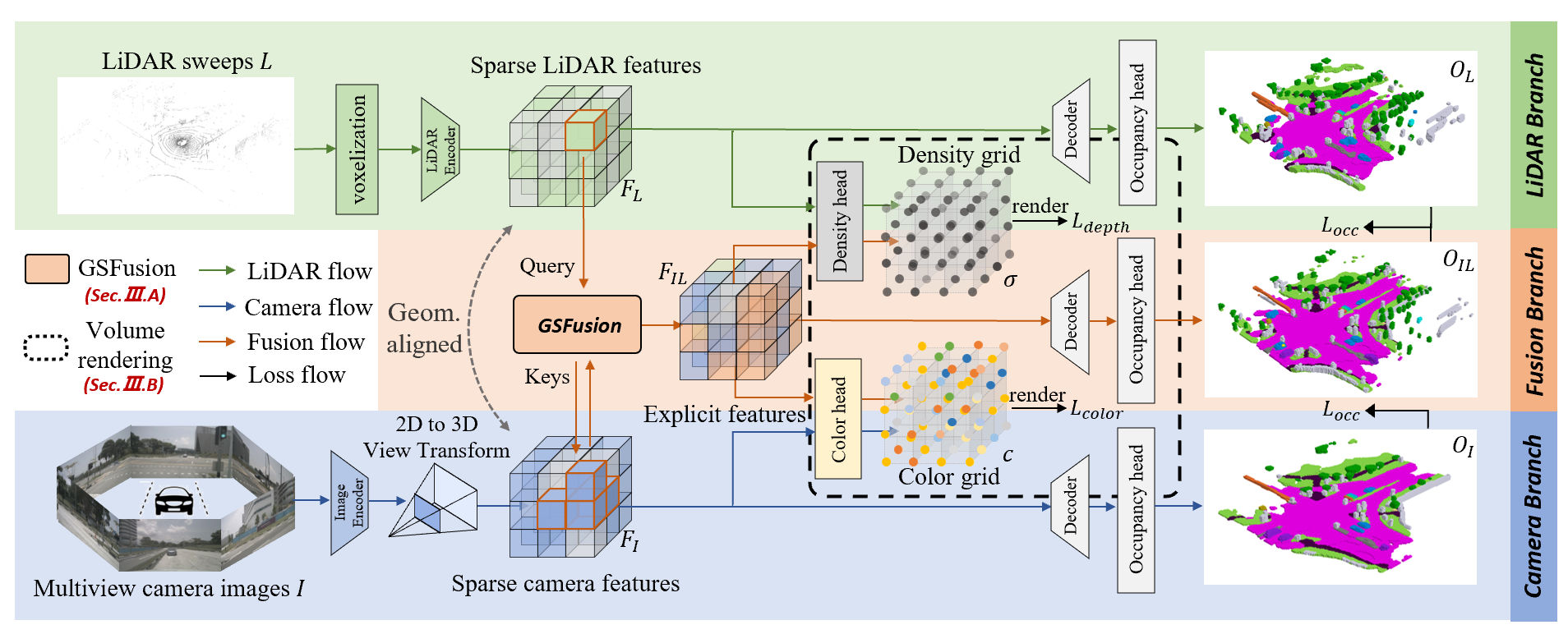
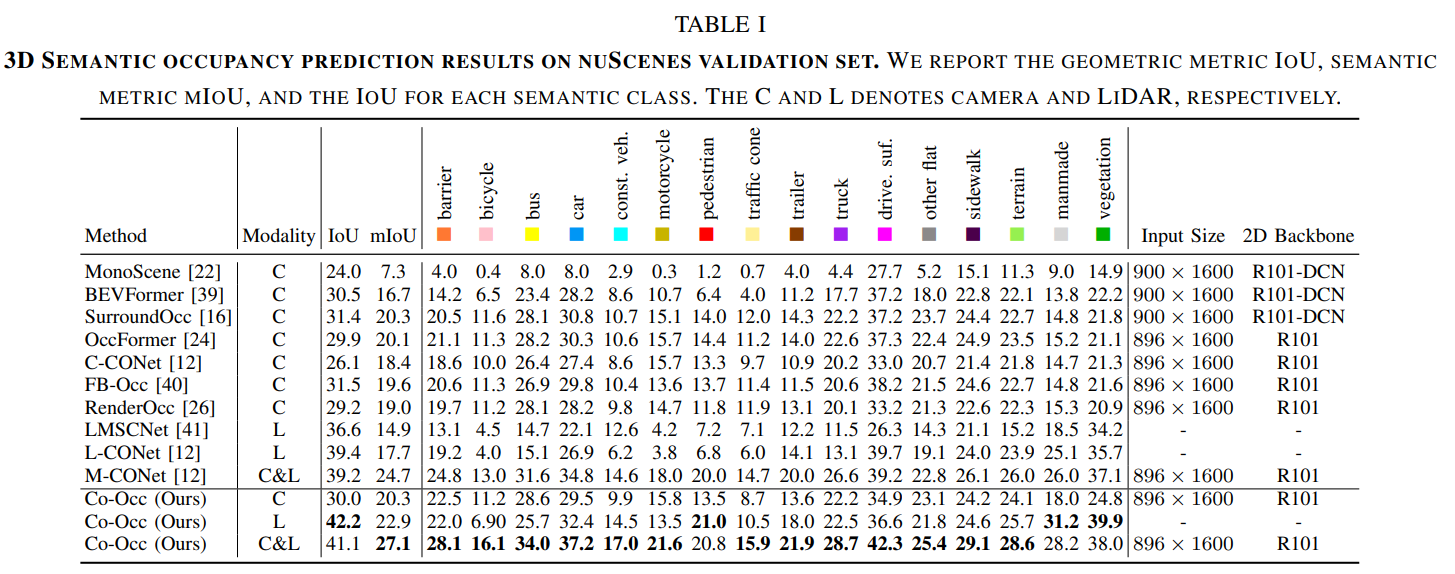
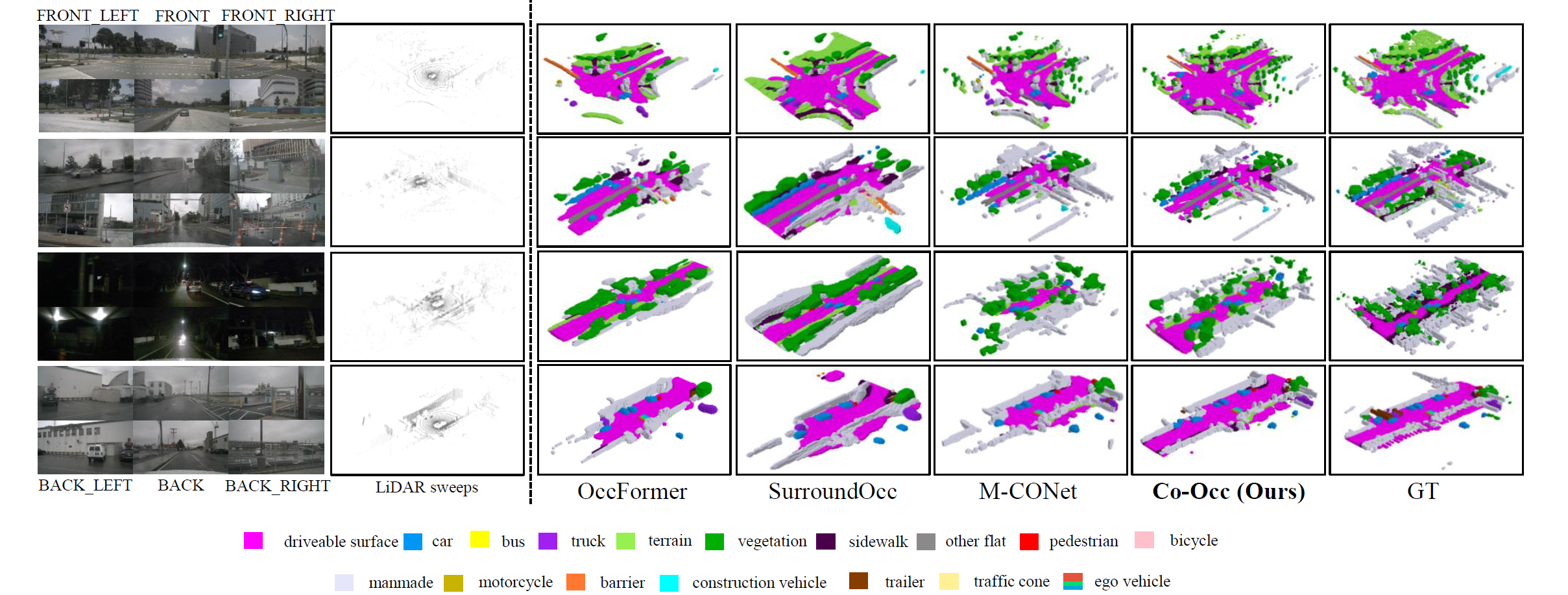
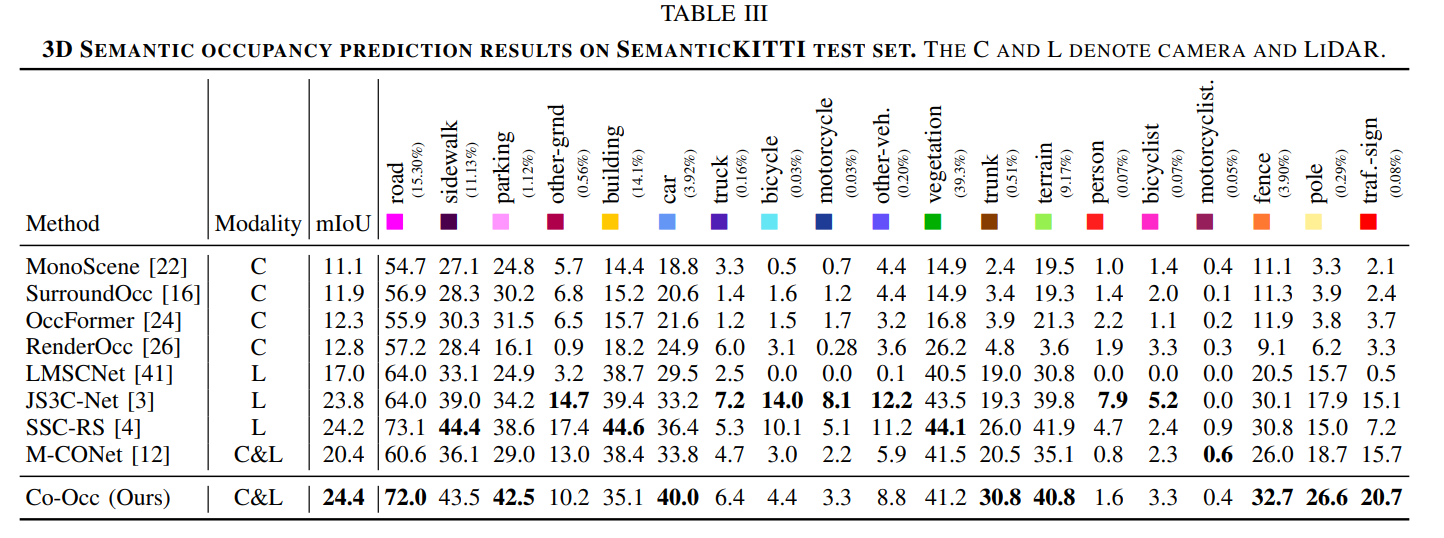
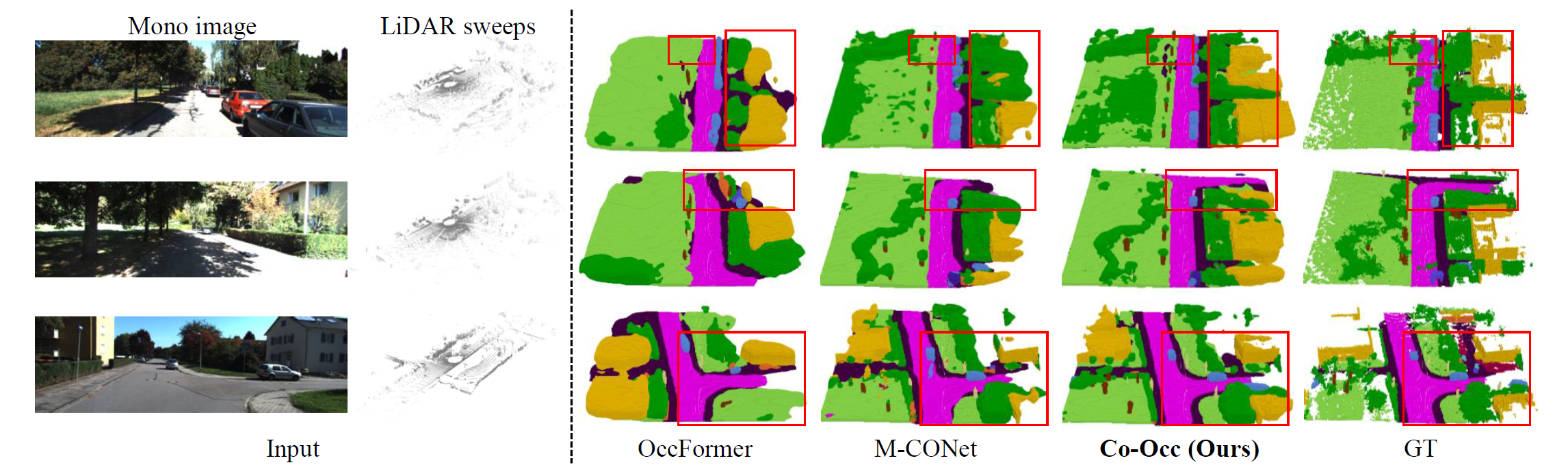
3D semantic occupancy prediction is a pivotal task in the field of autonomous driving. Recent approaches have made great advances in 3D semantic occupancy predictions on a single modality. However, multi-modal semantic occupancy prediction approaches have encountered difficulties in dealing with the modality heterogeneity, modality misalignment, and insufficient modality interactions that arise during the fusion of different modalities data, which may result in the loss of important geometric and semantic information. This letter presents a novel multi-modal, i.e., LiDAR-camera 3D semantic occupancy prediction framework, dubbed Co-Occ, which couples explicit LiDAR-camera feature fusion with implicit volume rendering regularization. The key insight is that volume rendering in the feature space can proficiently bridge the gap between 3D LiDAR sweeps and 2D images while serving as a physical regularization to enhance LiDAR-camera fused volumetric representation. Specifically, we first propose a Geometric- and Semantic-aware Fusion (GSFusion) module to explicitly enhance LiDAR features by incorporating neighboring camera features through a K-nearest neighbors (KNN) search. Then, we employ volume rendering to project the fused feature back to the image planes for reconstructing color and depth maps. These maps are then supervised by input images from the camera and depth estimations derived from LiDAR, respectively. Extensive experiments on the popular nuScenes and SemanticKITTI benchmarks verify the effectiveness of our Co-Occ for 3D semantic occupancy prediction.
@article{pan2024co,
title={Co-Occ: Coupling Explicit Feature Fusion With Volume Rendering Regularization for Multi-Modal 3D Semantic Occupancy Prediction},
author={Pan, Jingyi and Wang, Zipeng and Wang, Lin},
journal={IEEE Robotics and Automation Letters},
year={2024},
publisher={IEEE}
}